Eine kurze Einführung zu NoSQL
In der heutigen Zeit werden immer mehr Daten gesammelt. Dabei wird es wichtiger auf welche Art und Weise die Daten miteinander verknüpft sind. NoSQL Systeme können zum Speichern dieser Daten benutzt werden, wobei NoSQL kein klar definierter Begriff ist. Vielmehr gibt es Eigenschaften, welche sogenannten NoSQL Systemen gemeinsam sind:
a) nicht-relationale Datenmodelle:
Daten sind nicht in Relationen (Tabellen mit PK/FK - Beziehungen) abgelegt. Stattdessen haben sich vier Typen von Datenmodellen herausgebildet:
-
Documents
-
Graph
-
Wide-Column
-
Key-Value
b) Designt für (horizontales) Skalieren
NoSQL Systeme wurden (u. A.) entworfen, um auf extreme Datenmengen zu skalieren. Eine vertikale Skalierung (mehr RAM, Leistungsfähigere CPU, …) stösst irgendwann an die technischen Grenzen der verfügbaren Harware. NoSQL DB’s sind dagegen so entworfen, dass nach Bedarf weitere Knoten hinzugefügt (horizontale Skalierung) werden können. Die Design-Prinzipien (z. B. shared-nothing architecture) gehen oft einher mit hoher Verfügbarkeit und Performance.
c) Schema on Read (schemaless)
Das Datenschema ist nicht fix vorgegeben (z. B. fixe Anzahl Spalten). In einer DokumentenDB kann (im Extremfall) jedes Dokument eine andere Struktur haben (was allerdings nicht sehr nützlich wäre). Echte Daten aus Anwendungen haben immer gewisse Gemeinsamkeiten in ihrer Struktur (Schema). Schemaless gibt es nicht. Es heisst dann einfach, dass man beim Lesen der Daten "aufpassen" bzw. "arbeiten" muss (aka schema-on-read).
Neo4J Graph Database
Neo4J ist ein Werkzeug, um Daten abzuspeichern, die eine Graphen-ähnliche Struktur aufweisen. Zur Erinnerung:
Ein Graph ist eine endliche Menge von Punkten, wobei jedes Paar von zwei Punkten entweder durch eine Linie verbunden ist oder nicht.
Die Punkte werden in der Regel "Knoten" genannt, bei den Linien spricht man häufig von "Kanten". Ein "Knoten" entspricht einer Entity während die "Kanten" die Beziehungen zwischen den Entities darstellen. Um Verwechslungen mit dem Funktionsgraphen zu vermeiden, spricht man gelegentlich auch von Netzwerken.
Mit Neo4J Browser lassen sich solche Daten ablegen, abrufen sowie einfach und vielfältig darstellen. Hier klicken und die Datenplattform selber austesten.
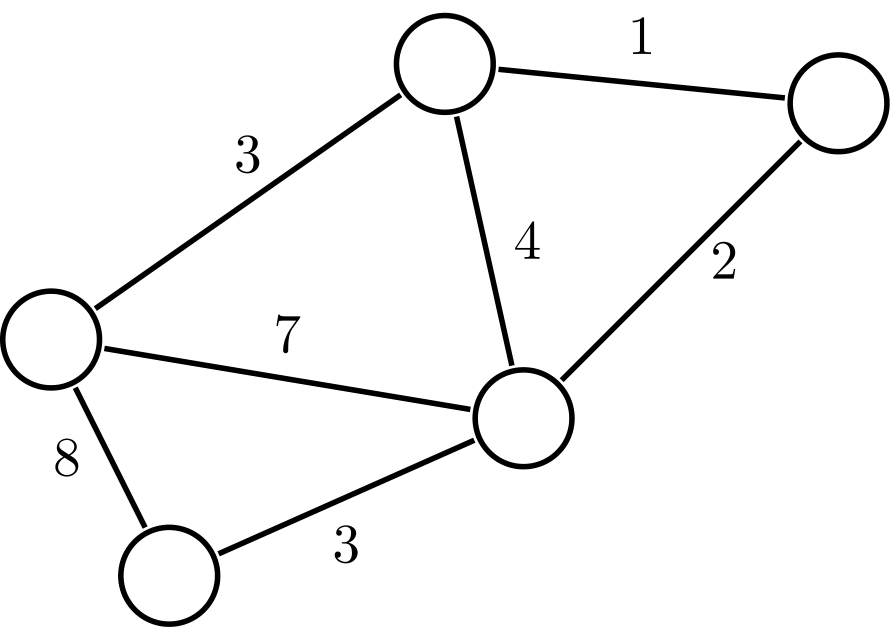
Zum Beispiel kann man alle Restaurants einer Stadt als Knoten abspeichern und diese durch gewichtete Kanten verbinden, welche die Reisezeit zwischen den Restaurants angeben. Mit Neo4J Bloom könnte man sich dann alle Restaurants anzeigen lassen, die in fünf Minuten erreichbar sind.
MongoDB Database
MongoDB ist ein plattformübergreifendes, dokumentenorientiertes NoSQL Datenbankprogramm. Es verwendet JSON-ähnliche Dokumente mit optionalen Schemas.
Die MongoDB Kommandozeile "mongosh" ist eine vollumfängliche JavaScript und Node.js Umgebung, um mit Datensätzen zu interagieren. Sie benutzt die vier grundlegenden Operationen "create", "read", "update" und "delete" (CRUD). Bei MongoDB Compass ist die Kommandozeile mongosh integriert.
Die Grundlagen
Bei der Arbeit mit MongoDB sind sechs grundlegende Konzepte zu verstehen.
- Innerhalb einer MongoDB Instanz kann man null oder mehr Datenbanken anlegen, die als Container für alles andere dienen.
- Eine Datenbank wiederum kann aus null oder mehr Kollektionen bestehen. Eine Kollektion hat viele Ähnlichkeiten zu einer gewöhnlichen Tabelle, dass man diese beiden Dinge ohne Bedenken als dasselbe betrachten kann.
- Dem Schema folgend, besteht eine Kollektion aus null oder mehr Dokumenten, die man als Zeile der Tabelle interpretieren kann.
- Ein Dokument besteht aus mindestens einem Feld, welches man als Spalte oder Kolonne der Tabelle anschauen kann.
- Indices in MongoDB verhalten sich sehr ähnlich wie ihre RDBMS (Relational Database Management System) Gegenstücke.
- Wenn man bei MongoDB Daten abfragt, erhält man als Rückgabewert einen Zeiger auf die Stelle in der Datenbank. Mit diesen Zeigern kann man Operationen machen, wie Zählen oder Überspringen, bevor man die eigentlichen Daten bezieht. Einen solchen Zeiger nennt man Cursor.
Eine Frage, die sich hier stellt, ist, warum man überhaupt so viele neue Begrifflichkeiten einführen sollte, anstatt direkt von Tabellen, Zeilen und Spalten zu sprechen. Der Hauptunterschied ist, dass die Spalten einer Tabelle bereits auf Stufe der Tabelle festgelegt werden müssen, wohingegen ein Feld erst auf der Stufe eines Dokuments definiert wird. In anderen Worten, Kollektionen können Dokumente mit unterschiedlichen Feldern beinhalten, während Tabellen nur Zeilen mit denselben Spalten haben können.
Sobald man die erste Kollektion erstellt, wird auch eine Datenbank angelegt.
Erwähnenswert ist die Kompatibilität mit der "upsert"-Anweisung. Mit diesem Befehl wird ein Element aktualisiert (“update”) sofern es vorhanden ist und falls nicht, wird es hinzugefügt ("insert"). Eine "join"-Anweisung fehlt hingegen. Ein Vorteil von MongoDB ist die Möglichkeit, räumliche Indices zu verwenden. Man kann also zum Beispiel in einem Dokument Felder für eine x- und eine y-Koordinate ablegen und dann Daten abrufen, die in der Nähe sind oder eine Bestimmte Distanz nicht überschreiten.
Die Dos and Don’ts beim Design einer Document-DB
Im Gegensatz zu relationalen Datenbanken sind Document-DBs sehr flexibel, was dem Entwickler mehr Freiheiten gibt. Trotzdem gib es einige Patterns, welche man beachten sollte.
Daten, die zusammen abgerufen werden, sollten zusammen gelagert werden, aber man sollte damit nicht zu weit gehen. Die Index-Performance sinkt bei steigender Dokumentgrösse. Ein Maximum von 16 MB pro Dokument wird daher empfohlen.
Do:
-
Daten, die häufig gemeinsam abgerufen werden, zusammen ablegen.
-
Nicht mehr als maximal 10'000 Kollektionen.
-
Ungebrauchte Kollektionen entfernen.
Don’ts:
-
Informationen in riesigen, endlosen Arrays ablegen.
-
Dokumente mit Daten aufblähen, die jedoch nicht zusammen abgerufen werden.
Kommentare