Softwareentwicklung mit OpenAI APIs
Im Moment ist das Thema KI in aller Munde und vor allem das Unternehmen OpenAI erfreut sich mit seinem KI-Modell ChatGPT sehr grosser Beliebtheit. Für uns bei M&F-Engineering ist der richtige Einsatz von künstlicher Intelligenz auch ein wichtiges Anliegen, um dadurch die besten Lösungen für unsere Kunden zu erarbeiten. Rainer Stropek hat uns in einem Praxisworkshop den Einsatz von OpenAI APIs in Softwareprojekten anhand von praktischen Beispielen nahegebracht. Mit über 25 Jahre Erfahrung als Unternehmer in der IT-Industrie und als Autor mehrerer Fachbücher und Artikel zu Themen wie Microsoft .NET, C#, Azure, Go und Rust besitzt Rainer Stropek einen sehr grossen Wissenshorizont und er wurde 2010 von Microsoft zu einem der ersten MVPs für die Azure-Plattform ernannt.
Thematisiert wurden dabei einerseits, welche Vorteile sich durch den Einsatz von ChatGPT in eigenen Projekten ergeben, andererseits aber auch Problematiken, welche bei der Implementierung oder in fertigen Produktivsystemen auftreten können. Der Workshop ging aber nicht nur auf die API des Chatbots ChatGPT ein, sondern auch Embedding-Vektoren, Assistenten und das Hosting eines eigenen ChatGPT Deployments in der Azure-Infrastruktur waren zentrale Punkte.
ChatGPT
Die Verwendung von ChatGPT auf der Webseite ist den meisten bereits bekannt und die Einsatzmöglichkeiten sind natürlich vielfältig. Auch unsere eigene Variante mit dem Namen "M&F GPT" erfreut sich intern unter den Arbeitskollegen grosser Beliebtheit und ist ein häufiges Gesprächsthema. Um ein tieferes Verständnis für die API des Chatbots und den zusätzlichen Funktionalitäten zu erhalten, drehte sich der erste Teil des Workshops darum, wie die API grundlegend verwendet wird und worauf man achten sollte. Dazu haben wir erst die Verwendung von simplen HTTP-Requests besprochen und anschliessend das Gelernte auch in einer .NET-Applikation umgesetzt. Hierbei ist es möglich, entsprechende Anfragen an OpenAI direkt zu versenden oder auch seine eigene Instanz des KI-Modells auf der Azure-Plattform zu hosten.
Das KI-Modell ist in mehreren Versionen verfügbar, dabei ist die Unterscheidung zwischen GPT3.5 und dessen Nachfolger GPT4 besonders wichtig. Die neuere Version GPT4 besitzt eine verbesserte Textgenerierung als ihr Vorgänger GPT3.5, jedoch ist die Generierung der Antwort mit einer höheren Wartezeit und höheren Kosten verbunden. Zu Beginn eines Projektes ist es daher sinnvoll abzuwägen, ob GPT4 einen entscheidenden Mehrwert bieten kann oder GPT3.5 auch ausreichend ist und natürlich, ob das Budget des Projektes die höheren Kosten von GPT4 tragen kann. Bei beiden KI-Modellen wird der Gesprächsverlauf nicht persistent gespeichert und behalten, daher ist es nötig, zu jeder Anfrage auch den vorherigen Chatverlauf anzuhängen, wodurch es erst möglich wird, ein fliessendes Gespräch mit dem KI-Modell zu führen.
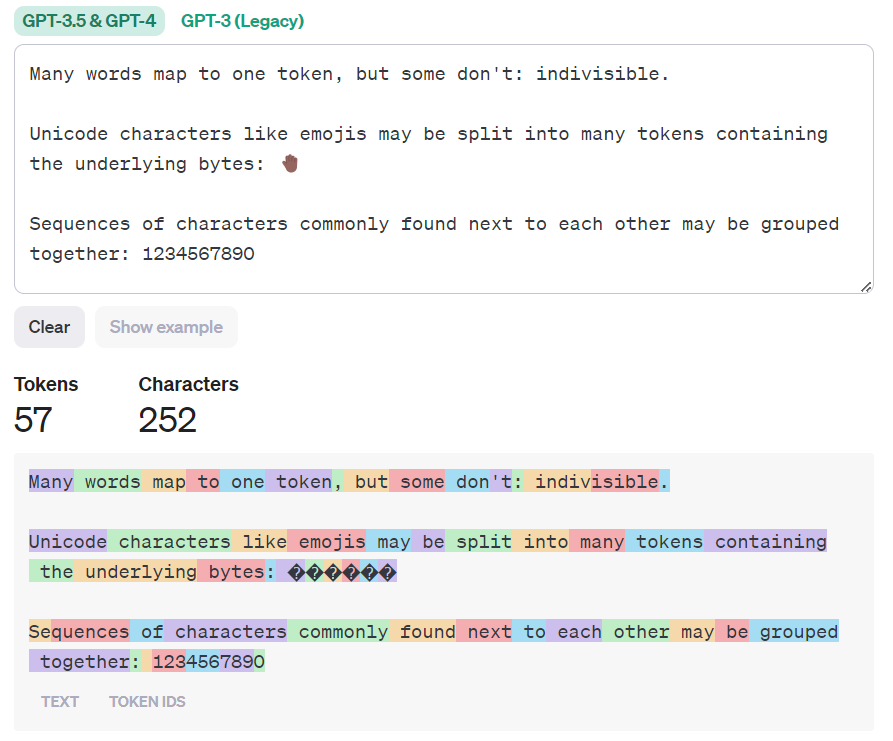
Zu Beginn wird der API ein sogenannter System-Prompt übergeben, welcher die Aufgabe des KI-Modells beschreibt und zusätzliche Informationen enthält, welche wichtig für die Beantwortung von Fragen des Anwenders sind. Texte des Chatverlaufs und der System-Prompt werden in sogenannte "Tokens" aufgeteilt und diese bilden die Basis zur Berechnung der anfallenden Kosten. Als Faustregel entsprechen vier Buchstaben in etwa einem Token. OpenAI selbst bietet einen interaktiven Tokenizer an, womit man einen Text zerlegt in farblich markierte Tokens anzeigen lassen kann. Die verschiedenen Versionen des KI-Modells selbst besitzen auch jeweils ein Token-Limit, welches die maximale Anzahl an Tokens darstellt, die von Modell pro Anfrage berücksichtigt werden können.
Function-Calling
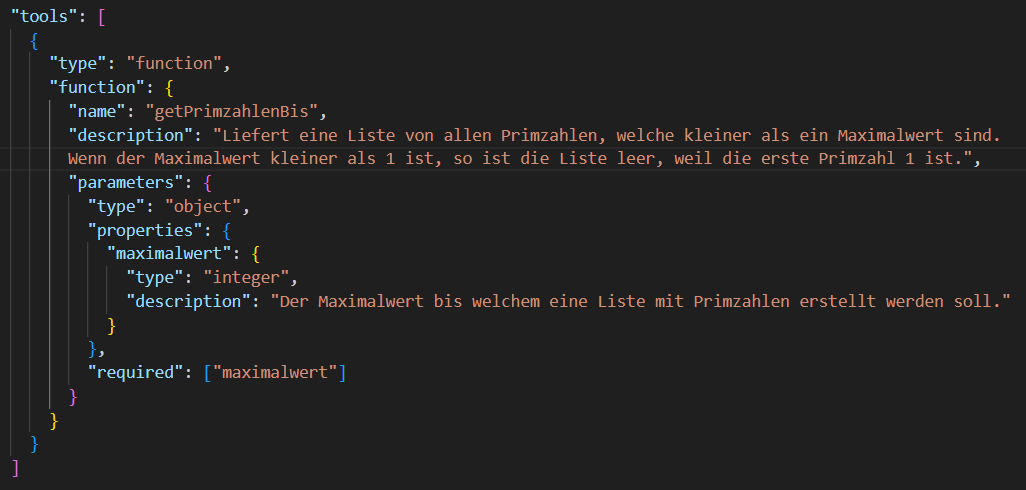
Der Chatbot kann auch durch eigene Funktionen erweitert werden, was Function-Calling genannt wird und im API-Aufruf als Tool definiert werden kann. Eine Funktion kann in einer beliebigen Programmiersprache implementiert werden. Entscheidend dabei ist es, einen selbsterklärenden Namen und eine möglichst genaue Beschreibung für die Funktion zu wählen, denn anhand dieser entscheidet das KI-Modell dann selbstständig, wann eine Funktion aufgerufen werden soll und auch welche Eingabeparameter es der Funktion mitgeben will. Dies bietet entscheidende Vorteile an, wie das Auslesen von Daten aus einer eigenen Datenbank oder das Einpflegen von Daten in eine Datenbank. Auch das Bereitstellen von Echtzeitdaten oder Domain-spezifischen Funktionalitäten kann durch Function-Calling umgesetzt werden. Einige dieser Anwendungsbereiche könnte man auch umsetzen, indem man entsprechende Informationen in der System-Prompt notiert, jedoch sind schreibende Funktionalitäten, wie das Ablegen von Daten in eine eigene Datenbank, nur mit Function-Calling realisierbar. Das Hinterlegen von Informationen im System-Prompt verbraucht zusätzliche Tokens und wäre dementsprechend mit höheren Kosten verbunden.
Streaming
Bisher besprochene Ansätze generieren eine fertige Antwort auf dem Server und senden diese im Anschluss an uns zurück. Dabei ist im Vorfeld nicht klar, wie lange die Erstellung der Antwort dauert. Ein Anwender erhält dementsprechend auch kein Feedback und dies beeinflusst die Benutzerfreundlichkeit unserer Anwendung negativ. Abhilfe schafft die Streaming-Funktionalität der API, welche es möglich macht, generierte Antworten Stück für Stück zu erhalten, sobald sie auf dem Server generiert wurden. Dies ist den Benutzern der ChatGPT-Webseite bereits bekannt und auch in eigenen Anwendungen wird dies durch Streaming möglich. In der Implementierung macht man sich dafür die asynchrone Programmierung zunutze. Über Websockets kann man die erhaltenen Antwortstücke dann in Echtzeit an den Anwender weitergeben und ein Benutzererlebnis schaffen, wie man es von ChatGPT kennt.
Assistenten
Assistenten der Assistant API sind die neueste Erweiterung von OpenAI und die API befindet sich zum Zeitpunkt der Erstellung dieses Blogbeitrags noch in der Beta. Aus Anwendersicht ist hier von GPTs die Rede und ChatGPT-Plus Kunden können diese auf der Webseite auch bereits ausprobieren. Die Idee hinter den GPTs oder Assistenten ist es, dass man dem KI-Modell einen starken und gut formulierten System-Prompt zu einem Themengebiet bereitstellt, wodurch treffendere Antworten von höherer Qualität generiert werden können. Ein Assistent kann mit weiteren Werkzeugen ausgestattet werden, wie das Hochladen von Dokumenten mit relevanten Informationen (retrieval-tool) oder das Bereitstellen von Funktionen, wie wir es bereits angesprochen haben (function-calling). Ruft ein Benutzer nun einen dieser Assistenten auf, so wird im Hintergrund ein sogenannter Thread gestartet, wodurch der Gesprächsverlauf ohne zusätzlichen Aufwand persistiert wird.
Der Anwender kann dem Assistenten Fragen stellen und der Assistent generiert eine passende Antwort dafür. Pro Frage des Anwenders wird zum Generieren der Antwort ein sogenannter Run gestartet und es ist möglich zwischen zwei Runs bestimmte Konfigurationen am KI-Modell zu ändern, wie zum Beispiel die Umstellung des verwendeten Modells von GPT3.5 auf GPT4, ohne dabei den Kontext des Gesprächsverlaufs zu verlieren. Streaming wird bei Assistenten noch nicht unterstützt, wodurch Polling nötig ist, um Antworten abzufragen.
Durch die Einführung von Assistenten möchte sich OpenAI mehr an die Endanwender richten und Anwender können zu unterschiedlichen Themenbereichen jeweils den passenden Assistenten konsultieren. Diese Entwicklung ist nicht nur spannend zu beobachten, sondern natürlich auch für uns als Entwickler von grosser Relevanz.
Embeddings und RAG-Pattern
Embeddings oder Embedding Vektoren sind Repräsentationen von Daten als n-dimensionale Vektoren von Gleitkommazahlen. OpenAI benutzt Embeddings in Form von 1536-dimensionalen Vektoren, um Texte zu codieren, welche dann von ChatGPT verwendet werden. Auch kann man sich über die API von OpenAI eigene Embeddings erstellen lassen, wozu man aus Kostengründen das Modell "text-embedding-ada-002" verwenden sollte. Die erhaltenen Embedding Vektoren sind normalisiert, wodurch die Vektoren mathematisch gesehen stets eine Länge von eins besitzen. Die Kosinus-Ähnlichkeit bzw. der Winkel zwischen zwei Embedding Vektoren ist dann das Mass dafür, wie ähnlich sich die beiden Vektoren sind.
Erstellt man von Textabschnitten oder möglichen Antworten Embedding Vektoren, so lassen sich diese mit dem Embedding Vektor einer konkreten Fragestellung vergleichen und dadurch ist es möglich, relevante Textabschnitte zur konkreten Fragestellung zu identifizieren. Durch Einpflegen der relevantesten Textstellen in den System-Prompt der Fragestellung kann das KI-Modell mit Informationen erweitert werden und diese dann in der generierten Antwort verwenden.
Es wird dadurch die Intelligenz der Embedding Vektoren zur Auswahl von relevanten Textabschnitten aus Dokumenten mit der Intelligenz der Generierung einer Antwort von ChatGPT kombiniert, um eine deutlich bessere Antwort zu erhalten. Das KI-Modell mit relevanten Textabschnitten zu einer entsprechenden Fragestellung zu erweitern und dem Modell dadurch besseren Kontext zu geben, nennt man Retrieval Augmented Generation (RAG).
Eine grosse Herausforderung hierbei ist es, eine gute Aufteilung von Dokumenten zu finden, um aus den einzelnen Textteilen im nächsten Schritt Embedding Vektoren zu erstellen. Grosse Dokumente müssen in kleinere Textabschnitte aufgeteilt werden, um daraus Embedding Vektoren zu erstellen, denn durch das Token-Limit der Modelle ist die Länge der Eingabe zum Erstellen von Embedding Vektoren limitiert. Zudem müssen Dokumente mit komplexen Layouts und Informationen in Form von Bildern, Grafiken oder Diagrammen im Vorfeld vorbereitet werden, um bessere Embedding Vektoren zu generieren, welche später mit einer Fragestellung verglichen werden können.
Diverse Strategien zum Aufteilen von Dokumenten können verwendet werden:
- nach einer festgelegten Länge wie die Anzahl von Buchstaben
- semantische Aufteilung durch Sätze, Paragrafen oder Abschnitte
- themenbasiert Aufteilung nach bestimmten Themengebieten
- abfragebasierte Aufteilung, wenn Fragen der Anwender im Vorfeld bekannt sind
- hybride Ansätze aus den anderen Strategien
Das Embedding Modell sieht immer nur den gerade verarbeiteten Teil eines Dokuments und weiss nichts über den Text davor oder danach. Deshalb ist das Aufteilen von Dokumenten nicht trivial, denn es muss darauf geachtet werden, dass der Kontext in den einzelnen Textabschnitten erhalten bleibt und Referenzierungen auf vorherige Textstellen, für sich alleine genommen, in den einzelnen Textabschnitten auch noch Sinn ergeben. Unterm Strich ist das Aufteilen von Dokumenten zum Erstellen von guten RAGs mit Aufwand verbunden, weil es eine detaillierte Auseinandersetzung mit den Dokumenten voraussetzt und in einigen Fällen ist eine manuelle Bearbeitung durch einen Menschen unumgänglich.
Azure OpenAI
Im letzten Teil haben wir einen Einblick erhalten, wie sich Instanzen von OpenAI's GPT-Modell auf der eigenen Azure-Infrastruktur bereitstellen lassen. Auch hier konnten wir vom Expertenwissen von Rainer Stropek profitieren und sowohl das manuelle Deployment über die Webseite erlernen, als auch die Automatisierung durch Bicep-Skripte. Eine weitere Thematik war das Absichern dieser Instanzen vor unbefugten Zugriffen Dritter und welche Aspekte es beim Betreiben eines Produktivsystems zu beachten gibt.
Teilnehmer Statement
Das Thema KI ist in der heutigen Zeit omnipräsent und ich bin begeistert von einem Experten in diesem Themengebiet so viele wertvolle Einblicke erhalten zu haben. Ich nehme aus diesem Praxisworkshop ein besseres Verständnis für die interne Funktionsweise des KI-Modells ChatGPT und die Verwendung der bereitgestellten API mit. Dadurch lassen sich Anwendungsfälle leichter erkennen und diese auch besser in Softwareprojekte einbinden, wodurch bessere Lösungsansätze gefunden werden können.
Weiterführende Links
Rainer Stropek https://rainerstropek.me/
OpenAI API Docs https://platform.openai.com/docs/overview
OpenAI API Tutorial von Rainer Stropek https://github.com/rstropek/sus-openai-api-tutorial
AzureAI automatisches Deployment von Rainer Stropek https://github.com/rstropek/Samples/tree/master/KI/OaiAzure
OpenAI Tokenizer https://platform.openai.com/tokenizer
Verfügbare Modelle https://platform.openai.com/docs/models
Kommentare