Docker und Kubernetes
Die Möglichkeiten der Containerisierung haben die Art und Weise, wie Anwendungen entwickelt und bereitgestellt werden, verändert. Docker und Kubernetes sind heutzutage allgegenwärtig und werden nahezu synonym mit Containerisierung und Container-Orchestrierung verwendet. Golo Roden gab uns in einem zweiteiligen Workshop eine Einführung in beide Technologien. Er ist Founder, CTO, und Managing Partner der Firma the native web, welche Beratung im Bereich Software Architektur, Prozess Evaluation und Unterstützung in der Entwicklung von Software anbietet.
Docker
Im ersten Teil ging es um Docker. Doch wieso gibt es überhaupt Docker und welches Problem wird damit gelöst?
Wir kennen es alle. Code soll von A nach B bewegt werden, entweder um es zu deployen oder zum Testen auf dem Rechner eines Kollegen. Frei nach dem Motto “It works on my machine” können wir alle bereits Probleme bei diesem Vorgehen voraussehen, aufgrund unterschiedlicher Betriebssysteme, Softwareversionen, Konfigurationen etc.
Doch was bieten sich für Lösungen dafür an?
Ein **Installer** welcher alle relevanten Systemparameter überprüft und bei Bedarf Konfigurationen anpasst, ist komplex, umständlich und daher anfällig für Fehler.
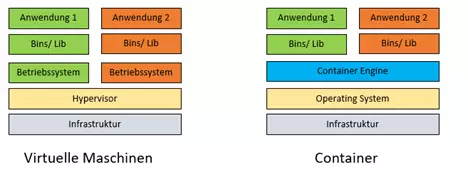
Eine virtuelle Maschine (VM) hingegen bietet ein Image als Vorlage, welches das Betriebssystem sowie alle notwendigen Konfiguration, Software etc. schon bereithält. Das auf einem solchen Image basierende System läuft dann auf einer emulierten Hardware. Gegen diesen Ansatz spricht jedoch der hohe Ressourcenverbrauch (CPU, RAM, Diskspace).
Linux bietet mit Linux Container (LXC) ein Konzept zur Isolation von Anwendungen, die alle auf dem gleichen Kernel laufen. Es ist leichtgewichtig, ermöglicht eine hohe Anzahl an Containern auf einem System und ist direkt in Linux integriert. Dies führt direkt zum großen Nachteil, dass es nur für Linux-Anwendungen anwendbar und kompliziert ist.
Docker greift das Konzept Linux Containern auf und ermöglicht es mit einer einfachen Bedienung, die Container auf Linux nativ laufen zu lassen. Auf Windows werden die Container in einer Linux VM gestartet.
Aufbau
Die Hauptkomponenten von Docker sind der Client, der Host und die Registry.
Der Benutzer interagiert vornehmlich mit dem Docker Client. Die Befehle vom Docker Client werden über eine REST API an den Docker Daemon gesendet, der die Container und Images auf dem Host verwaltet.
Die Docker Registry ist ein Verzeichnis von Docker Images. Ein bekanntes Beispiel einer solchen Registry ist Docker Hub, das öffentlich zugänglich ist.

Images
Ein Docker Image umfasst alle Abhängigkeiten eines Containers und erlaubt darüber hinaus auch die Erstellung von Instanzen. Viele Standard- Images, wie z.B. ubuntu, stehen auf Docker Hub zur Verfügung und können direkt oder als Basis für ein eigenes Image genutzt werden.
Des Weiteren kann ein Docker Image auch automatisch aus einem Dockerfile erzeugt werden. Das Dockerfile ist ein Textfile, welches den Aufbau eines Images beschreibt . Es enthält Befehle, welche ein Nutzer auch via Kommandozeile eingeben könnte.
Image bauen: docker build . [--no-cache] [-t <name>:<version>]
Da Docker Images keine Kernel, Treiber sowie Systemd/Init Dateien usw. beinhalten müssen, sind sie gegenüber den VM Images bedeutend kleiner (Ubuntu Server 22.04 LTS ist 2 GB, ubuntu:22.04 image ist 77.8 MB.)
Container
Der Aufbau eines run Befehls für einen Docker Container sieht grundsätzlich folgendermassen aus:
docker run <flags> <image> <cmd> Beim <image> handelt es sich um die Kopiervorlage.
docker run -it ubuntu bashAm obigen Beispiel möchte ich aufzeigen, welche Prozesse bei der Ausführung des Befehls ablaufen.
-
Zuerst wird überprüft, ob lokal bereits ein Image von Ubuntu vorhanden ist. Falls dies nicht der Fall sein sollte, wird das Image von der Registry heruntergeladen (entspricht docker pull ubuntu).
-
Docker erzeugt nun einen neuen Container
-
In einem nächsten Schritt richtet Docker ein Dateisystem für den Container ein. Als Grundlage dient das angegebene Image. Im laufenden Container können nach belieben Dateien und Verzeichnisse erstellt, verändert und gelöscht werden. Diese Änderungen haben nur Auswirkungen auf das Dateisystem des Containers, das zugrundeliegende Image bleibt dagegen unverändert.
-
Da keine Netzwerkoptionen angegeben wurden, wird eine Netzwerkschnittstelle erstellt und Docker weist dem Container eine IP-Adresse zu. Standardmäßig verbindet sich der Container über die Netzwerkverbindung des Host-Rechners mit externen Netzwerken.
-
Als vorerst letzten Schritt startet Docker den Container und führt bash aus. Da der Container interaktiv läuft und an das Terminal angeschlossen ist (aufgrund der -i und -t Flags), können wir Eingaben über Ihre Tastatur machen, während die Ausgabe am Terminal protokolliert wird.
-
Durch die Eingabe von exit wird bash beendet und der Container gestoppt, aber nicht entfernt. Dadurch kann er jederzeit erneut gestartet werden.
Natürlich kann der run Befehl auch komplizierter ausfallen. Folgend ein Befehl mit Portforwarding und einhängen eines Verzeichnisses.
docker run -it -d -p 8080:8080 -v "C:\Users\Public\Documents":usr/share/:ro ubuntu bashDa, wie oben erwähnt, die Container nicht sofort entfernt werden, nachdem sie beendet werden, muss man sie verwalten. Eine nicht abschliessende Auswahl an Befehlen folgt nachfolgend:
//Zeigt laufende Container an
docker ps
//Beendet laufende Container
docker stop <id> [<...id>]
//Beendet laufende Container unsanft, dafür sofort
docker kill <id> [<...id>]
//Entfernt beendete Container
docker rm <id> [<...id>]
//Zeigt lokal heruntergeladene Images an
docker images
//Entfernt nicht mehr benötigte Images
docker rmi <id> [<...id>]
//Lädt ein Image herunter, führt es aber nicht aus
docker pull <image>
//Räumt nicht mehr benötigte Artefakte auf
docker system prune
//Zeigt die Konsolenausgabe eines Containers an
docker logs <id>
Kubernetes
Das Verwalten von mehreren miteinander vernetzten Containern nur mit Docker kann schnell sehr aufwändig werden, da zusätzliches Tooling für Verwaltung von Containern, Netzwerken und volumes benötigt wird. Um dies zu Vereinfachen kann Kubernetes eingesetzt werden.
Kubernetes vereinfacht die Verwaltung komplexer containerisierter Anwendungen über verschiedene Umgebungen, wie z. B. physische, virtuelle und Cloud-basierte Infrastrukturen. Es bietet eine robuste Funktionssammlung, um Anwendungs-Bereitstellung, Skalierung und Hochverfügbarkeit zu unterstützen und somit die Verwaltung und Überwachung von containerisierten Anwendungen in größerem Umfang zu erleichtern.
Ursprünglich von Google entwickelt, wird es nun von der Cloud Native Computing Foundation (CNCF) gewartet.
Der Name Kubernetes ist dem Griechischen entlehnt und bedeutet so viel wie "Steuermann". Die vielfach anzutreffende Abkürzung K8s leitet sich dadurch ab, dass einfach die 8 Buchstaben "ubernete" im Wort Kubernetes durch "8" ersetzt werden.
Architektur
In Zusammenhang mit Kubernetes ist es wichtig, die zugrundeliegende Architektur zu verstehen. Kubernetes besteht aus mehreren Kernkomponenten, die zusammenarbeiten, um Container und ihre Lebenszyklen zu verwalten.
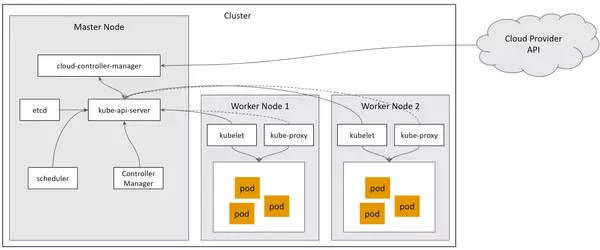
Hier ist ein kurzer Überblick über die Hauptkomponenten und Konzepte:
-
Nodes: Sogenannte Worker-Maschinen, auf denen Container bereitgestellt werden. Ein Node kann sowohl eine physische als auch eine virtuelle Maschine sein. Sie sind für das Ausführen der Container, das Verwalten von Speicher, Netzwerken und anderen Ressourcen, die für die Pods erforderlich sind, verantwortlich.
-
Master-Node: Der Master-Node dient als Steuerungsebene für den gesamten Kubernetes-Cluster. Er verwaltet clusterweite Operationen, Scheduling und Kommunikation.
-
Pods: Sie sind die kleinsten Kubernetes-Objekte und umfassen einen laufenden Container oder eine Gruppe eng zusammengehörender Container. Die Container innerhalb eines Pods teilen Ressourcen und können über lokale Netzwerkschnittstellen untereinander kommunizieren.
-
ReplicaSets: Sie stellen sicher, dass immer eine festgelegte Anzahl identischer Pods ausgeführt wird. Damit können sie eine hohe Verfügbarkeit und Ausfallsicherheit gewährleisten.
-
Deployments: Sie verwalten den Lebenszyklus von Pods, indem sie sicherstellen, dass sowohl eine gewünschte Anzahl von Replikationen läuft als auch Aktualisierungen sowie Rollbacks von Anwendungsversionen durchgeführt werden.
-
Services: Services bieten einen stabilen Endpunkt im Netzwerk, um auf eine Gruppe von Pods zugreifen zu können. Sie ermöglichen Lastenausgleich und stellen eine nahtlose Kommunikation zwischen verschiedenen Komponenten einer Anwendung sicher.
-
Volumes: Volumes dienen zur Speicherung und gemeinsamen Nutzung von Daten zwischen Containern innerhalb von Pods. Dabei werden verschiedene Speichervarianten unterstützt, wie z. B. lokaler Speicher oder Cloud-basierter Speicher.
-
Namespaces: Durch den Einsatz von Namespaces können Ressourcen innerhalb eines Clusters logisch isoliert und organisiert werden. Ausserdem ermöglichen sie die Zuweisung von Zugriffssteuerungen und Ressourcenkontingente für verschiedene Gruppen oder Teams.
Kubernetes unterstützt verschiedene Container-Laufzeiten, einschließlich Docker, containerd und CRI-O, und kann lokal oder auf verschiedenen Cloud-Providern bereitgestellt werden. Es bietet einen deklarativen Ansatz zur Definition und Verwaltung von Anwendungen mithilfe von YAML- oder JSON-Konfigurationsdateien, was eine einfache Automatisierung und Reproduzierbarkeit ermöglicht.
Anbei eine unvollständige Liste einiger wichtiger Befehle:
//Worker-Nodes auflisten
kubectl get nodes [-o wide]
//Namespace anlegen
kubectl create namespace <name>
//Namespace auflisten
kubectl get namespaces
//Namespace löschen
kubectl delete namespace <name>
//Manifest anwenden (erzeugen oder ändern)
kubectl apply -f <manifest>
//Manifest löschen
kubectl delete -f <manifest>Scaling und Loadbalancing
Kubernetes bietet die Möglichkeit die Anzahl an Anwendungs-Replicas je nach Bedarf einfach zu erhöhen oder zu verringern. Durch diese horizontale Skalierungsfunktion kann die Anwendung Ressourcen effizienter nutzen und sich automatisch an Änderungen der Workload anpassen.
Ausserdem enthält es auch einen Loadbalancing-Mechanismus, bei welchem der Datenverkehr gleichmässig auf mehrere Instanzen der Anwendung verteilt wird. Durch die gewährleistete gleichmässige Lastverteilung wird sowohl die Gesamtperformance als auch deren Verfügbarkeit sowie Ausfallsicherheit verbessert.
Fazit
Zusammenfassend, bietet Docker den grossen Vorteil Anwendungen und ihre Abhängigkeiten in einem einziges Paket (Image) zu verpacken. Es beinhaltet alles, das für die Ausführung der Anwendung erforderlich ist, einschließlich der Laufzeitumgebung und aller weiteren Abhängigkeiten. Das Betriebssystem stellt Mechanismen bereit, durch die eine Isolierung der Container erreicht werden kann. Dadurch sind sie skalierbarer und leichtgewichtiger als VMs, was zu einer effizienten Ressourcennutzung führt. Kubernetes dagegen vereinfacht die Verwaltung von solch containerisierten Anwendungen in dynamischen und hochbeanspruchten Umgebungen durch Bereitstellen einer skalierbaren und stabilen Plattform. Im Zusammenspiel kann damit die zugrunde liegende Infrastruktur abstrahiert werden und somit die Entwicklung, Bereitstellung wie auch Verwaltung von Anwendungen vereinfacht werden.
Kommentare